
BeautifulSoup
아래와 같은 simple.html 파일이 있다.
이 파일을 파이썬에서 그대로 불러오고 싶을 때 사용하는 방법이 두 가지가 있다.
<!DOCTYPE html>
<html lang="ko">
<head>
<meta charset="utf-8"/>
<title>간단한 html</title>
<style>
h1 { color: red; }
p {color: green; }
.animal {color: blue; }
.fruit {color: orange; }
#cat {color:brown;}
table, th, td {
border : 1px solid black;
border-collapse : collapse;
}
#books b {
background-color: cyan;
}
</style>
</head>
<body>
<h1>header</h1>
<p>This is a paragraph</p>
<div>이것은 <br> div 입니다</div>
<ul>
<li class="animal">dog</li>
<li class="animal" id="cat">cat</li>
<li class="animal">frog</li>
<li class="animal">this</li>
</ul>
<ul>
<li class="fruit">apple </li>
<li class="fruit">ba<b>nana</b></li>
</ul>
<ol>
<li><a href="https://www.naver.com" title="최고포탈">네이버</a></li>
<li><a href="https://www.daum.net">daum</a></li>
<li class="animal">fish</li>
</ol>
<hr>
<table id="books">
<thead>
<tr>
<th>제목</th>
<th>가격</th>
</tr>
</thead>
<tbody>
<tr>
<td>1.이것이 파이썬이다</td>
<td><b>[도서]</b> 19,200원</td>
</tr>
<tr>
<td>2.저것도 파이썬이다</td>
<td><b>[할인]</b> 12,800원</td>
</tr>
<tr>
<td>3.그래도 파이썬인가?</td>
<td><b>[중고]</b> 6,500원</td>
</tr>
</tbody>
</table>
</body>
</html>
데이터 파싱 하기
우선 현재 경로에 있는 simple.html 내용을 가져오는 것이니 with as를 사용하여 파일 자체를 읽어온다.

BeautifulSoup 파싱 라이브러리를 사용하면 손쉽게 html, json, xml 파일 등을 파싱 할 수 있다.
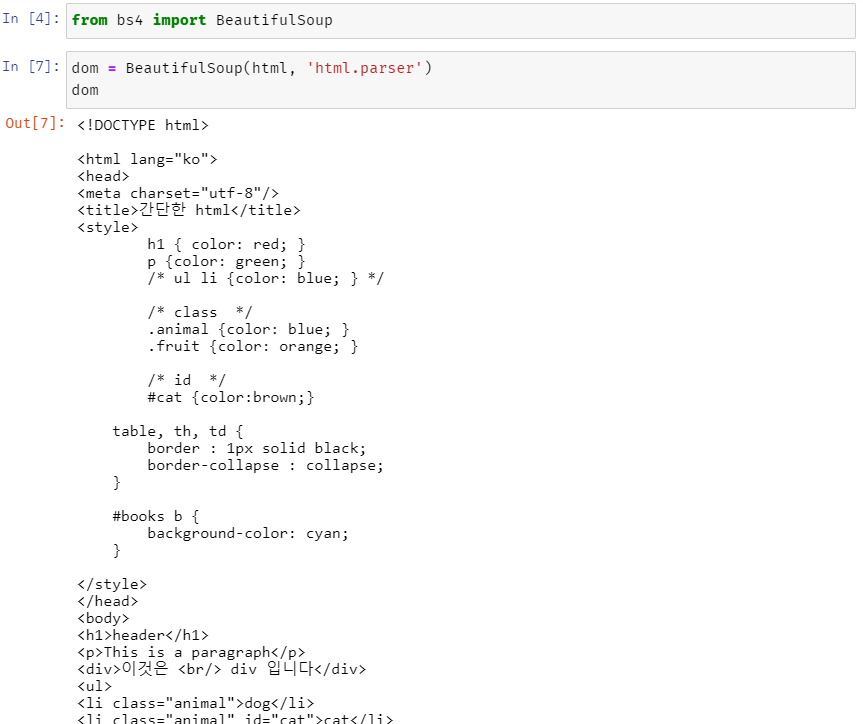
In [7]에서 보이는 코드는 아까 읽어온 html 데이터를 html 문서로 파싱 한 뒤 Document Object Model 객체(DOM)를 표현하는 BeautifulSoup 객체를 생성한다. 그리고 그렇게 생성된 객체를 dom 변수에 저장한다.

저장된 객체의 type을 확인해보면 bs4.BeautifulSoup인 것을 확인할 수 있다.
select()와 select_one()
BeautifulSoup 객체에서는 CSS selector로 select 된 element를 가져올 수 있다.
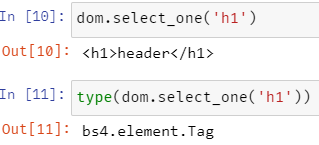
select_one()은 select된 첫 번째 element를 한 개 리턴한다.

select()는 select된 모든 element들의 list를 리턴한다.
만약 한 개도 select 되지 않았다면 비어있는 list를 리턴한다.
이와 다르게 select_one()은 select 된 게 없다면 None을 리턴한다.

select()는 list로 받아오기 때문에 index 값을 사용해 값에 접근할 수 있다.
.text
지금까지 불러온 element들은 모두 태그가 붙어있는 형태였다.
.text를 사용할 경우 특정 element의 content만을 불러올 수 있어, 태그는 제거된 형태로 값을 가져올 수 있다.
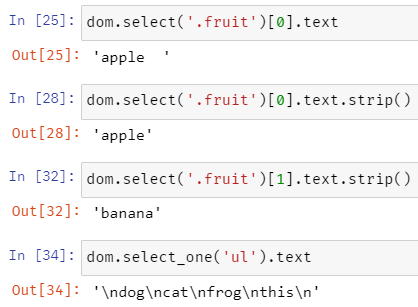
아까 일부러 apple 뒤에 공백을 넣었는데 이는 알아서 제거해주지 않으니 웬만하면 strip() 함수를 사용하여 가져오는 값의 좌우 공백을 제거해주는 것이 좋다.
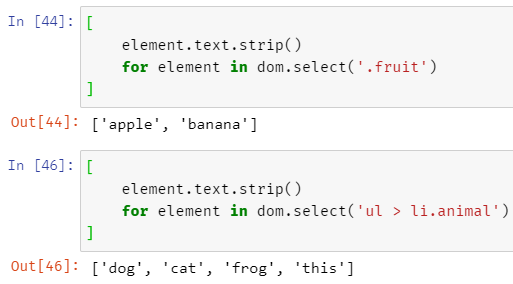
List Comprehension을 활용하여 원하는 형태로 값을 저장할 수도 있다.
.attrs
지금까지는 태그 안에 있는 내용들만 가져왔는데 내용들만이 아닌 태그의 속성 값을 가져오고 싶을 수도 있다.
그때 .attrs를 사용하면 된다. 기본적으로 key-value 쌍으로 하여 dict 타입으로 나온다.
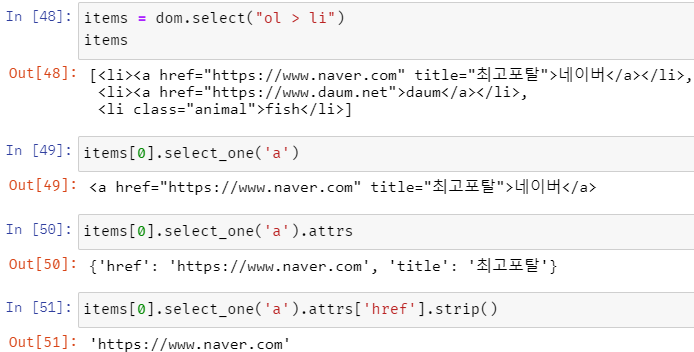
순차적으로 코드가 어떻게 진행되는지 보기 위해 풀어 적은 것이다.
In [48] dom 객체에서 원하는 값을 뽑아 items에 저장한다.
이때 items는 element 객체인데, element 객체에서 다시 select()와 select_one()이 사용 가능하므로 In [49]에서 items에 저장된 내용 중 첫 번째 내용에서 a 태그에 관한 내용만 뽑아온다.
이후 In [50]에서 .attrs를 사용해 attribute를 key-value 쌍으로 뽑아낸다.
In[51]에서는 .attrs로 얻어온 데이터 값들 중 key 값이 'href'인 값의 value를 가져온다.
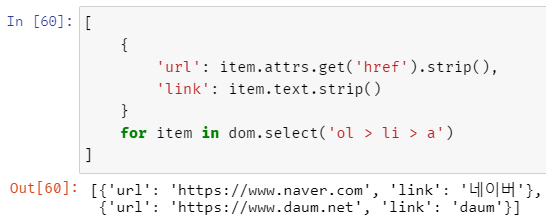
List Comprehension을 사용해 원하는 dict 형태로 데이터를 저장할 수 있다.
decompose()
element를 가져왔을 때 가져온 element 내에 원하지 않는 element가 들어있을 수도 있다.
element 안의 element를 삭제하기 위해 decompose()를 사용한다.
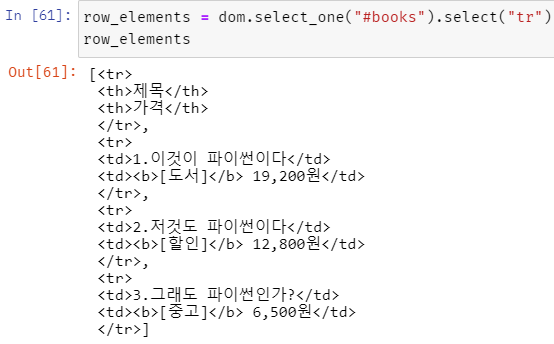
위의 내용에서 <b> 태그 내에 있는 값들만 삭제하고 데이터로 저장하고 싶다.

In [62]와 In [63]은 같은 코드이다. CSS selector를 조금 다르게 설정했다.
CSS를 사용할 때와 마찬가지로 first-child, last-child 사용이 가능하다.
위 출력 부분에서 내용에 들어있는 [도서], [할인], [중고] 문자열 부분을 제거하려고 한다.
마침 해당 부분들은 <b> 태그로 감싸 져 있다.
코드 예

제거하려는 문자열이 <b> 태그 내에 있으니 select_one('b').decompose()를 사용하면
가져온 element 값에서 b 태그인 부분을 제거하게 된다.
파싱 한 데이터를 DataFrame으로 만들기
pandas를 사용하면 손쉽게 DataFrame으로 만들 수 있다.
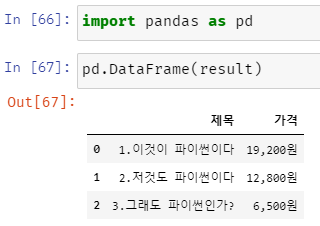
만약 위와 같은 상태에서 가격을 float 타입으로 변환하고 싶다면
replace() 함수와 float() 함수를 사용하면 된다.
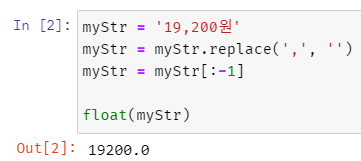
replace() 함수를 사용하여 중간에 들어있는 ,를 빈 문자열 ''로 대체한다.
마지막에 붙어있는 '원'을 제외하기 위해 마지막 문자열 전까지의 값을 가져오도록 [:-1]로 슬라이싱 한다.
마지막으로 float() 함수로 형 변환해주면 간단하게 변경할 수 있다.
코드 정리

위와 같이 원하는 데이터를 파싱 혹은 크롤링해서 DataFrame으로 만들고, 데이터를 다뤄볼 수 있다.