
동일한 테이블을 두 번 참조해야 할 때
예를 들어, 다음과 같은 두 개의 테이블이 있다고 가정한다.
create table board ( -- 게시글 정보 저장
uid int not null auto_increment comment 'pk', -- uid
b_cate_th1_cd varchar(10) not null comment '공통코드 1차', -- 카테고리 1
b_cate_th2_cd varchar(10) not null comment '공통코드 2차', -- 카테고리 2
title varchar(100) not null comment '제목',
content text comment '내용',
regdt date default (current_date) comment '등록일자'
writer varchar(100) comment '작성자'
constraint pk_board primary key(uid)
);
create table pc ( -- 공통코드
grp_cd varchar(100) not null comment '그룹코드',
cmm_cd varchar(10) not null comment '공통코드',
cmm_cd_nm varchar(50) not null comment '공통코드명',
reg_dttm datetime default (current_time) comment '등록일시',
constraint pk_pc primary key(grp_cd, cmm_cd)
);공통 코드 데이터를 담는 테이블 pc가 있고, 게시글 정보를 담는 테이블 board가 있다.
이때 게시판 테이블은 카테고리를 대분류, 중분류로 하여 두 가지 값을 갖기 때문에 카테고리와 관련하여 b_cate_th1_cd와 b_cate_th2_cd 두 개의 칼럼이 존재한다.
이와 관련하여 공통 코드에 들어가는 데이터이다.
-- 직업 카테고리
insert into pc (grp_cd, cmm_cd, cmm_cd_nm)
values ('b_cate_th1_cd', '01', '서머너');
insert into pc (grp_cd, cmm_cd, cmm_cd_nm)
values ('b_cate_th1_cd', '02', '소서리스');
insert into pc (grp_cd, cmm_cd, cmm_cd_nm)
values ('b_cate_th1_cd', '03', '도화가');
-- (직업 카테고리 내) 분류 카테고리
insert into pc (grp_cd, cmm_cd, cmm_cd_nm)
values ('b_cate_th2_cd', '01', '공략');
insert into pc (grp_cd, cmm_cd, cmm_cd_nm)
values ('b_cate_th2_cd', '02', '잡담');
board 테이블에는 b_cate_th1_cd와 b_cate_th2_cd 칼럼에 저장되는 값이 01, 02(코드 값, pc 테이블에서의 cmm_cd 값과 같음) 일 것이다.
사용자 화면에서는 카테고리가 코드 값(01, 02 등)으로 보이면 안 되고, 서머너, 공략과 같은 문자열로 보여야 한다.
따라서 pc 테이블의 cmm_cd_nm 데이터를 가져와야 하기 때문에 board 테이블에 있는 데이터 출력 시 pc 테이블과 조인해야 한다.
서머너, 소서리스, 도화가 같은 대분류 카테고리를 위해서 pc 테이블과 조인해야 되고(b_cate_th1_cd), 공략, 잡담과 같은 중분류 카테고리를 위해 pc 테이블을 한 번 더 조인해야 된다(b_cate_th2_cd).
동일한 두 테이블을 두 번 이상 조인하기 위한 쿼리는 두 가지 방법으로 작성해볼 수 있다.
첫 번째 방법은 from 절에서 같은 테이블 두 개를 join 하는 것이고,
두 번째 방법은 select 절에 서브 쿼리(스칼라 서브 쿼리)로 원하는 값을 출력하는 것이다.
첫 번째 방법
select
b.uid
, p1.cmm_cd_nm as category
, p2.cmm_cd_nm as sub_category
, b.title
, b.content
, b.regdt
from board b
join pc p1
on p1.cmm_cd = b.b_cate_th1_cd
join pc p2
on p2.cmm_cd = b.b_cate_th2_cd
where
p1.grp_cd = 'b_cate_th1_cd'
and p2.grp_cd = 'b_cate_th2_cd'
;from 절에서 pc 테이블을 총 두 번 조인한다.
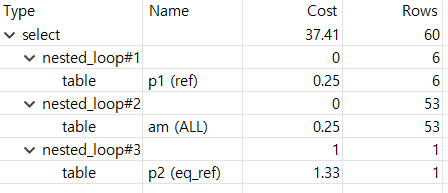
실행 계획은 위와 같다. (am 테이블은 본 예제에서 board 테이블과 같은 것이다.)
두 번째 방법
select
b.uid
, (
select p.cmm_cd_nm
from pc p
where p.grp_cd = 'b_cate_th1_cd'
and b.b_cate_th1_cd = p.cmm_cd
) as category
, (
select p.cmm_cd_nm
from pc p
where p.grp_cd = 'b_cate_th2_cd'
and b.b_cate_th2_cd = p.cmm_cd
) as sub_category
, b.title
, b.content
, b.regdt
from board b
;select 절 내에 서브 쿼리를 사용하여 필요한 카테고리명 값만 가져온다.
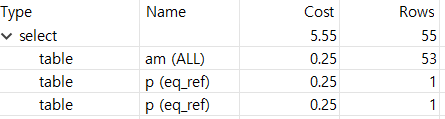
서브 쿼리 사용 시 실행 계획은 위와 같다.

두 쿼리의 소요 시간 차이이다. 서브 쿼리를 사용한 것보다 조인을 사용하는 게 시간이 두 배 정도 더 소요된다.
일반적으로 조인보다 서브 쿼리의 성능이 더 안 좋다고 생각하지만 인덱스 설정 시 스칼라 서브 쿼리가 더 빠른 경우도 존재한다. 스칼라 서브 쿼리에서 인덱스로 설정되어 있는 칼럼이 where절의 조건으로 들어가는 경우 조인 연산보다 빠를 수 있다. 위 상황에서는 grp_cd 칼럼이 pk이므로 인덱스로 설정되어 있기 때문에 조인 연산보다 빠르게 수행되는 것이다.
또한 스칼라 서브 쿼리의 장점으로는 캐싱 기능을 꼽을 수 있는데, 쿼리 수행 횟수를 최소화하기 위해 입력 값과 출력 값을 내부 캐시에 저장해두므로 내부 캐시에 (입력 값-출력 값)이 존재하는 경우 더 빠르게 실행될 수 있다.
스칼라 서브 쿼리는 메인테이블에서 서브 쿼리로 입력되는 값이 중복이 많은 경우 유리하게 작용한다. 위와 같은 경우는 공통 코드 테이블에서 코드 명칭을 가져오는 것(중복이 많음)이므로 스칼라 서브 쿼리를 사용하는 것이 더 유리하다.
일반적으로 스칼라 서브 쿼리는 조인 연산에 비해 실행 시 하드웨어 자원(메모리)이 더 많이 필요하다.
대부분의 튜닝 글을 보아도 조인으로 바꿀 수 있는 서브 쿼리는 조인으로 변경하여 쿼리를 작성하라고 한다. 그리고 조인을 사용하는 것이 더 빠르다고 말한다.
그러나 위처럼 무조건적으로 조인이 서브 쿼리보다 좋은 성능을 내고, 무조건적으로 속도가 더 빠른 것은 아니다.
개인적인 생각으로는 쿼리 작성이 제일 케바케가 많은 것 같다..